
January 10, 2025
【事例紹介】能動学習による超大規模低分子化合物のドッキングプラットフォーム
Kubernetes を基盤とする大規模バーチャルスクリーニング創薬プラットホーム(XEDOCK)の開発
近年の薬品研究開発コストの増大に対し、計算機を用いて市販化合物ライブラリやバーチャルライブラリのような分子プールから薬剤候補化合物を絞り込むバーチャルスクリーニングは、化合物の合成や生物試験といった実世界での実験の必要性が下がるため、経済的、時間的に探索研究の効率化が図れると期待されています。
1.巨大化する化合物ライブラリに対応するバーチャルスクリーニングとプラットフォーム
人間がバーチャルライブラリを半マニュアルで作成/選抜することもありますが、多くは、既存の各製薬会社が持っている化合物ライブラリや、ChEMBL、PubChemなどのパブリックライブラリ、試薬会社が提供する化合物ライブラリを使うことが多いです。化合物の活性予測は、すでに得られている構造活性相関から統計学的方法で予測したり、分子ドッキングなどの構造ベースの予測方法などが適用されることがほとんどです。
近年、それらのライブラリが巨大化しているため、大きなデータセットを効率的に扱うプラットフォームが必要になっています。データセットが大きくなると使用するメモリ、ストレージ、計算リソース(CPU/GPU)が多くなるため、それらのリソースを適切に配分する必要があります。
1.1.Kubernetes を基盤とするバーチャルスクリーニングプラットフォーム
Kubernetes は、コンテナベースのオーケストレーションプラットフォームで、コンテナ化されたアプリケーションを大規模に管理し、スケーラビリティを実現するものです。元々はGoogle が開発したシステムですが、現在はCloud Native Computing Foundationの 基盤としてコミュニティベースで多くのパブリッククラウドサービス(AWS, Azure, GCPなど)がその機能の一つとして提供しており、さまざまな環境へ対応することが可能です。また、各マイクロサービスが別のコンテナに閉じているため、再現性のないバグによる障害やリソース不足、プリエンプションによる急なシャットダウンがあっても、自動的に再実行するなどの高可用性も持ち合わせています。
ゼウレカでは、大規模な化合物ライブラリのバーチャルスクリーニングプラットホームとして、Kubernetes をマイクロサービスの基盤としたXEDOCKシステムを開発しました。これは、簡単な設定ファイルをアップロードすることにより、ワンクリックでドッキングを分散処理、実行するようなシステムです。計算資源は、キューに積まれているタスクの大きさと種類に応じた計算負荷に応じて計算資源を動的にスケーリングする仕組みになっているため、高負荷時には最大限、低負荷時には最低限のVMを確保するようになっています。
XEDOCKシステムは、ヘッドノードがマニフェストに記載した内容に従って、タスクをキューに送り、各マイクロサービスは、キューからタスクを受け取って処理していきます。単に大量のタスクを実行するだけでなく、キューを監視することにより、次の段階のタスクの進行状況に応じて次の別の工程につなぐようなことも可能です。
すべてのワーカーは再開ができるように実装しているため、ハードウエアの一時的障害やスポットインスタンスのプリエンプションやメモリリークなどの原因で不定期に発生するシャットダウンがあっても、再起動されるので全体のタスクは進行し続けます。
この仕組みは、分子ドッキングや機械学習モデルの構築など、並列に大量のタスクを実行することに向いています。
2.XEDOCKシステムの実行例
ここでは、AutoDock-Vinaを使ったドッキングを例にして説明します。
2.1.分子プール のアップロード
分子プールのフォーマットは、SDF、CSVなどです。
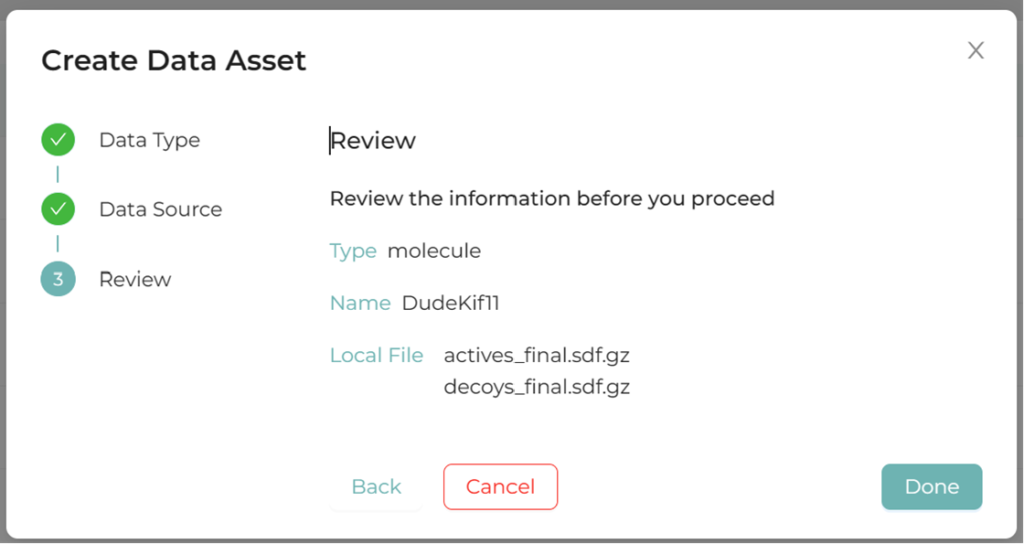 図1.XEDOCKにおける分子プールの登録画面
図1.XEDOCKにおける分子プールの登録画面
2.2.レセプターのアップロード
PDBあるいはPDBQTファイルをアップロードします。
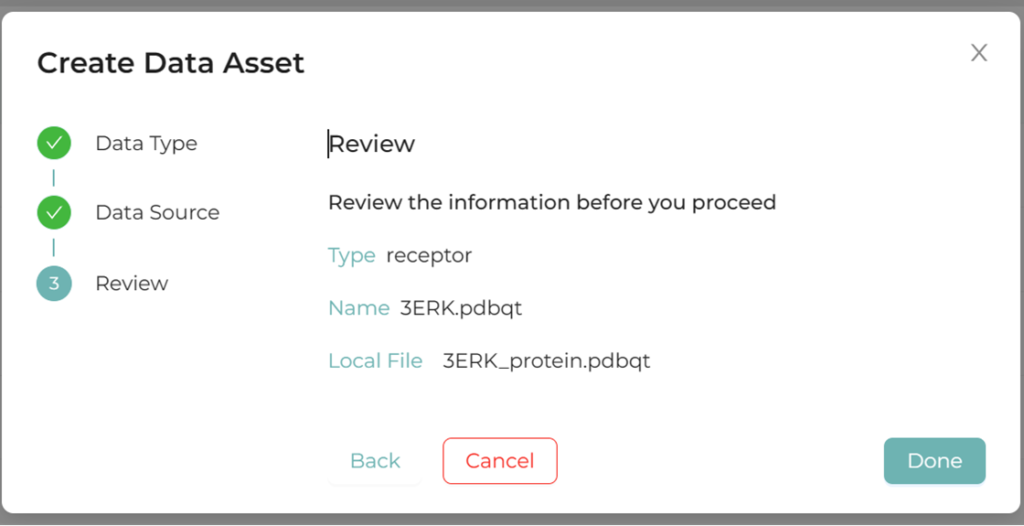 図2.XEDOCKにおけるレセプターの登録画面
図2.XEDOCKにおけるレセプターの登録画面
2.3.実験条件のアップロード
ドッキングの条件を表すマニフェストファイルは次のようになっています。
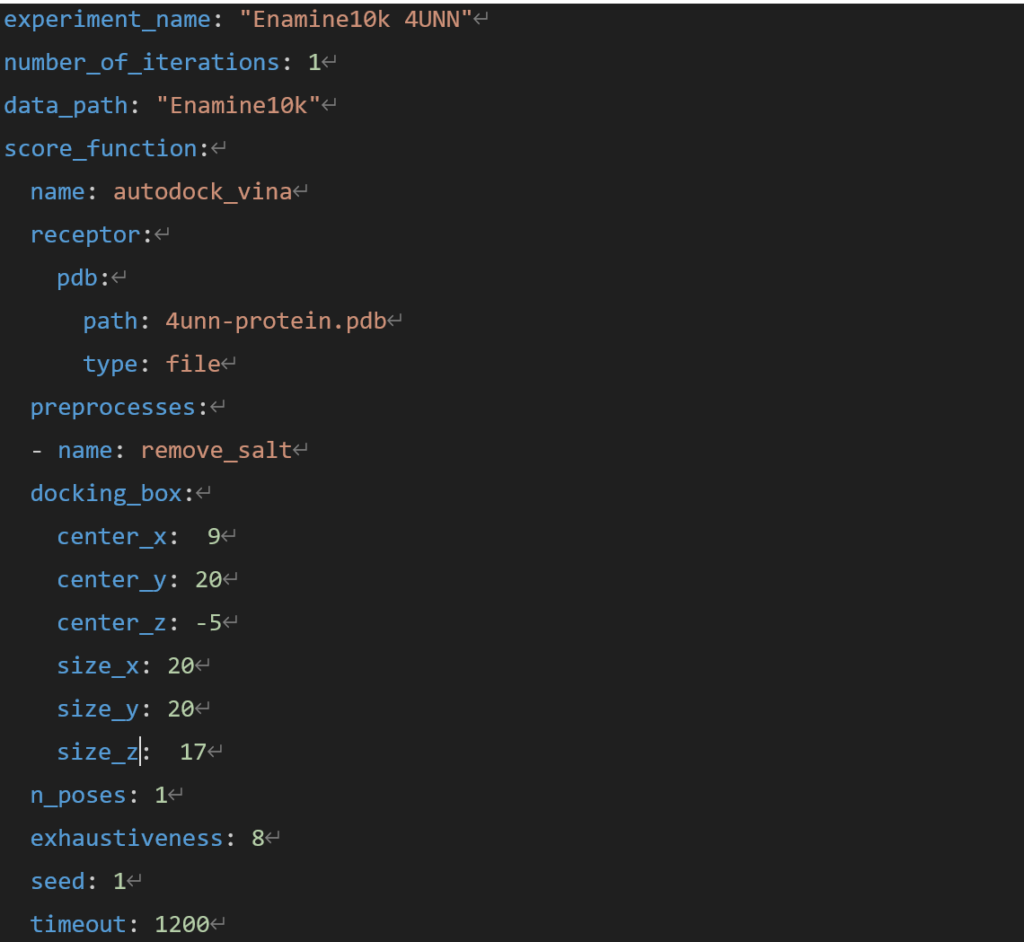 図3.XEDOCKのマニフェストファイルの例
図3.XEDOCKのマニフェストファイルの例
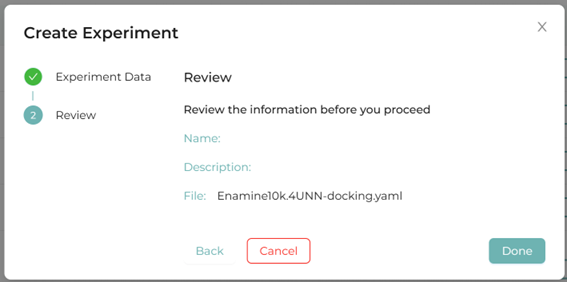 図4.XEDOCKにおけるマニフェストファイルの登録画面
図4.XEDOCKにおけるマニフェストファイルの登録画面
ドッキングが開始されると、クラウドからの計算資源の確保、アップロードされた分子プールのファイルに含まれているSMILESあるいはMolBlockからコンフォーメーションをの生成、AutoDock-Vinaが解釈できる形式(PDBQT)への変換、AutoDock-Vinaの実行、出力されたPDBQTファイルをSDFへ変換、といった一連の操作が実行されます。Microsoft Azure上(F16-v2 ×50 (スポットインスタンス))で実行したところ、25分で1万化合物のドッキングが完了しました。
実行の結果は、スコアのサマリーが含まれたCSVファイルと、一万のドッキングポーズをSDFとして出力します。
2.4.結果のサマリー
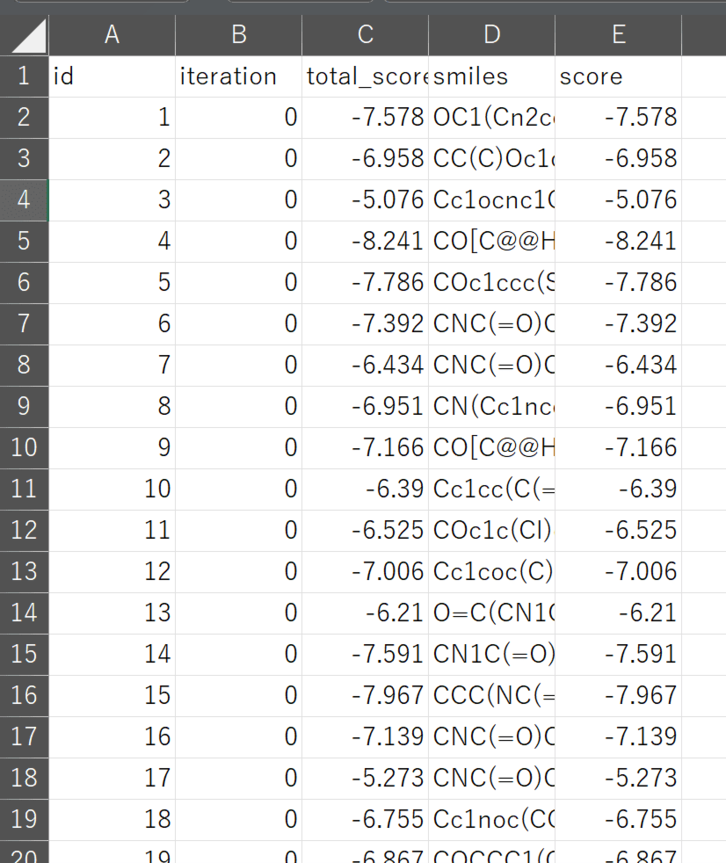
図5.XEDOCKの結果ファイルの例
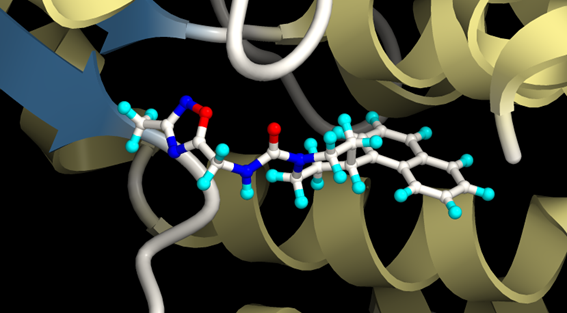 図6.XEDOCKの結果SDFからのドッキングポーズの描画の例
図6.XEDOCKの結果SDFからのドッキングポーズの描画の例
計算中に確保された計算資源は、ドッキングが終了すると、AKS(Azure Kubernetes Service) を通して開放されます。
2.5.応用例:ドッキング+能動学習
より複雑な応用として、プールベースの能動学習を活用したバーチャルスクリーニングを実施する例があります。
能動学習は、大量のデータの中からモデルにとって最も学習効果の高いデータを選び出し、効率的に学習させるものです。特にデータのラベル付けにコストがかかる場合に有効です。
分子ドッキングは計算量としては重い部類であり、ラベル付けにコストがかかると言えるため、能動学習に向いていると思われます。
XEDOCKシステムでは、軽い計算から重い計算、小さなデータセット~数億レコードを持つデータセットまで対応可能です。また、様々な能動学習アルゴリズム、予測モデル、化合物特徴量、スコア関数を備えており、それらを組み合わせて使用することができるようになっています。
さらに、あらゆる問題に対応できるような特徴量や予測モデルについても様々な方法で自動的に最適なモデルを選択、あるいは、アンサンブルするような機能なども設けています。
具体的な能動学習の流れは次のようになります。
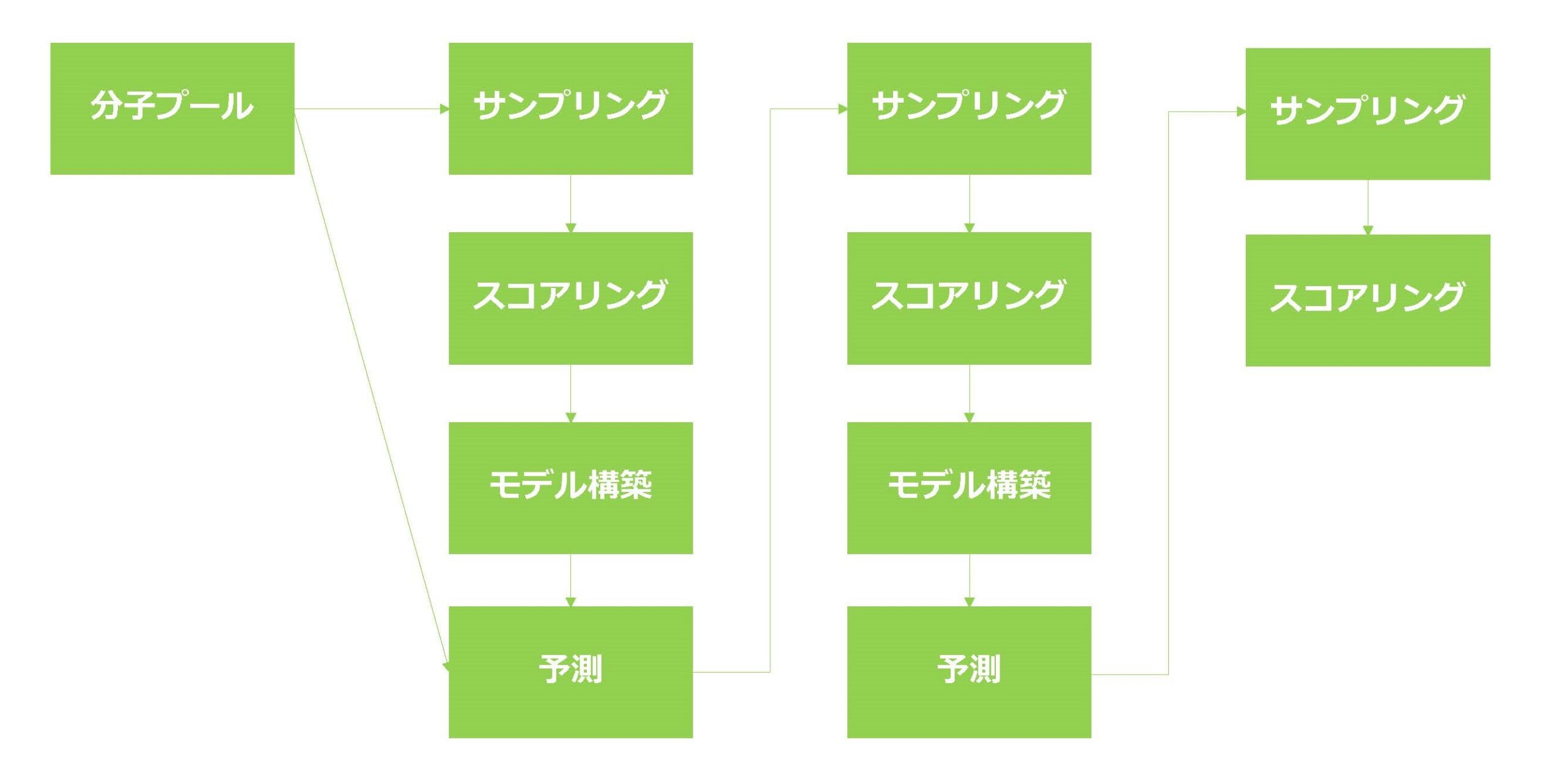 図7.能動学習の流れ
図7.能動学習の流れ
分子ドッキングに基づく能動学習には、サンプリング、ラベリング、モデル構築、予測と機能的に異なっている四つのマイクロサービスと、それらを制御監視するサービス(ヘッドノード)が必要です。
このようなワークフローは一つのプロセスでループを回すこともできますが、ゼウレカではこれをクラウドサービス上のマイクロサービスとして構築しました。能動学習だけではなくバーチャルスクリーニングに必要なアセット(分子ライブラリやレセプター)のクラウドへの登録などを含めたシステムになっています。XEDOCKシステムは様々なクラウドプラットフォームやオンプレミスな環境下でも容易にデプロイ可能なことも特徴の一つです。
先の例ではAzure上での実装でしたが、例えばAWSでは下記のような構成をしています。
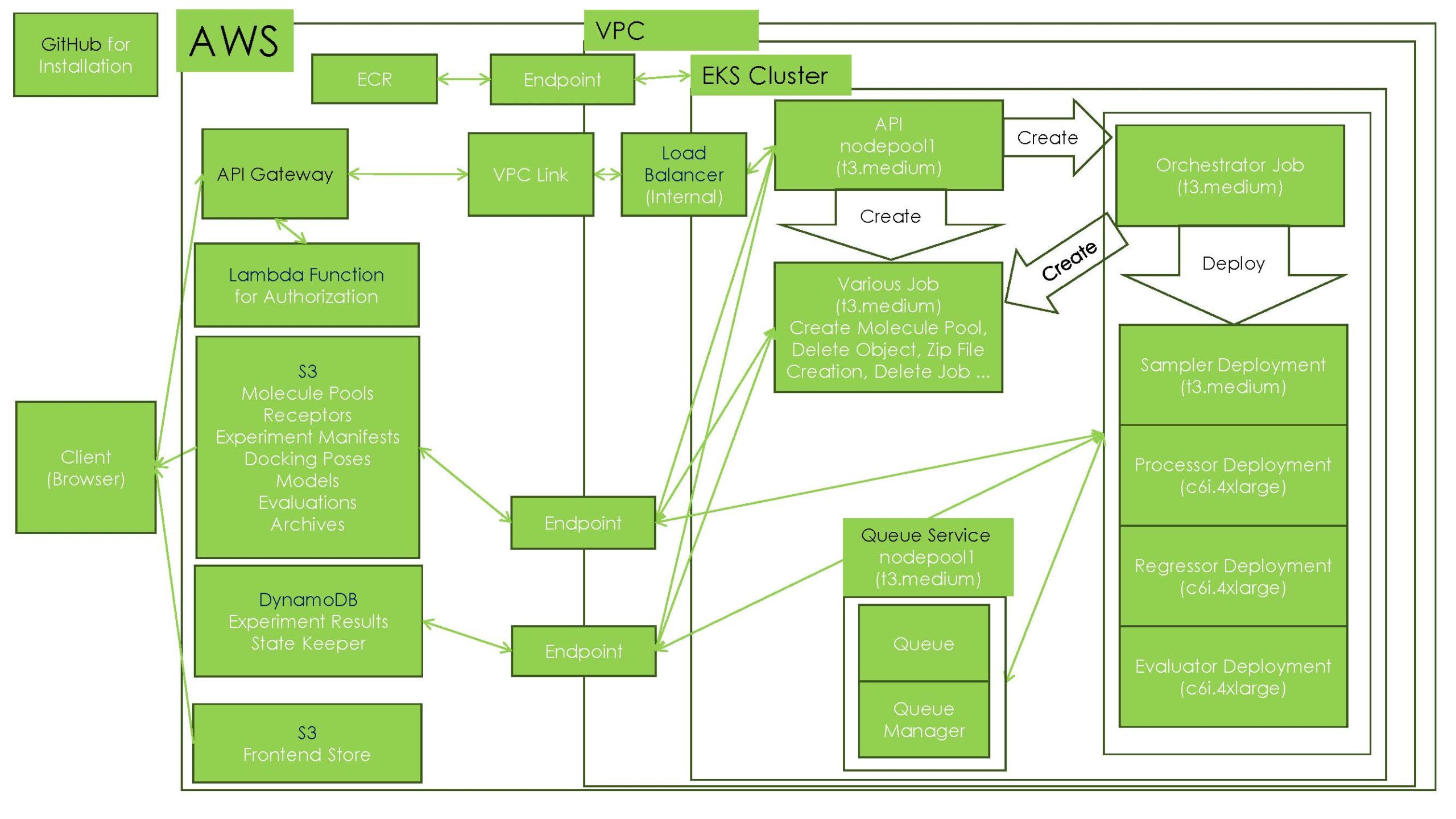 図8.AWS上でのXEDOCK構成例
図8.AWS上でのXEDOCK構成例
能動学習の実験を開始するAPIがコールされると、Orchestrator Jobが起動し、Queueサービスに必要なタスクのメッセージを送ります。Sampler, Processor, Regressor, Evaluatorの各マイクロサービスはQueueの状態に応じてスケーリングされ、各々がQueueからメッセージを受け取り、タスクを処理していきます。Orchestratorは全体を監視しながら、能動学習のフローを制御します。
3.能動学習の性能
能動学習は、構築されるモデルの性能の最大化を目的とすることが一般的ですが、バーチャルスクリーニングで使用する場合には、能動学習のループの中でより興味深い化合物がサンプリングされ、ラベリングされることが目的になっています。つまり、正確な予測を与える事も重要ですが、より興味深い化合物をより早く見つけることが重要になってきます。
XEDOCKシステムでは、様々な、化合物の特徴量や予測モデル、スコアリング(ドッキングソフトウェア等)、サンプリングに対応しています。また、特徴量と予測モデルについては、複数のモデルをトレーニングしたのちに最もよい性能を持ったものを選択するだけでなく、複数のモデルをアンサンブルするようなことも可能です。
 図9.XEDOCKで利用できる予測モデル・サンプリング手法
図9.XEDOCKで利用できる予測モデル・サンプリング手法
 図10.XEDOCKで利用できるスコアリング関数の例
図10.XEDOCKで利用できるスコアリング関数の例
3.1.XEDOCKシステムによる能動学習の例
ドッキングにおける能動学習において、よく研究されているベンチマークデータセットである、AmpCに対して1億化合物をDOCKでドッキングしたスコアのデータセットがあります。下記の例では、これを参照し 、全体で1億あるデータセットの中からDOCKのドッキングスコア上位1000個の化合物をどれだけ探索できるかを性能指標として計測しています。
近年、深層学習を基盤とする方法が化合物の物性予測でも能力を発揮することが注目されています。XEDOCKシステムでも、特徴量のマルチレイヤーパーセプトロンや、構造式のグラフ構造に注目したMPNNをサポートしています。それらは100000化合物のサンプリングを6回繰り返すという方法で、約70%と約100倍の濃縮性を示しました。
さらに、当社のプロトコルでは単純なフィンガープリント+古典的学習モデルより計算コストの低い方法を使ってループの回数を増やすと、より高い性能を示すことがわかりました。具体的には、先の例の1/10の一ループあたり10000化合物の評価を繰り返すという方法です。これにより30回で約70%、60回で約80%の、想定した化合物を得ることができました。つまり、全体の0.6%を見ることにより、上位0.001%の8割を捕捉できたことになり、ラベリングをすべき化合物が1/100倍になります。
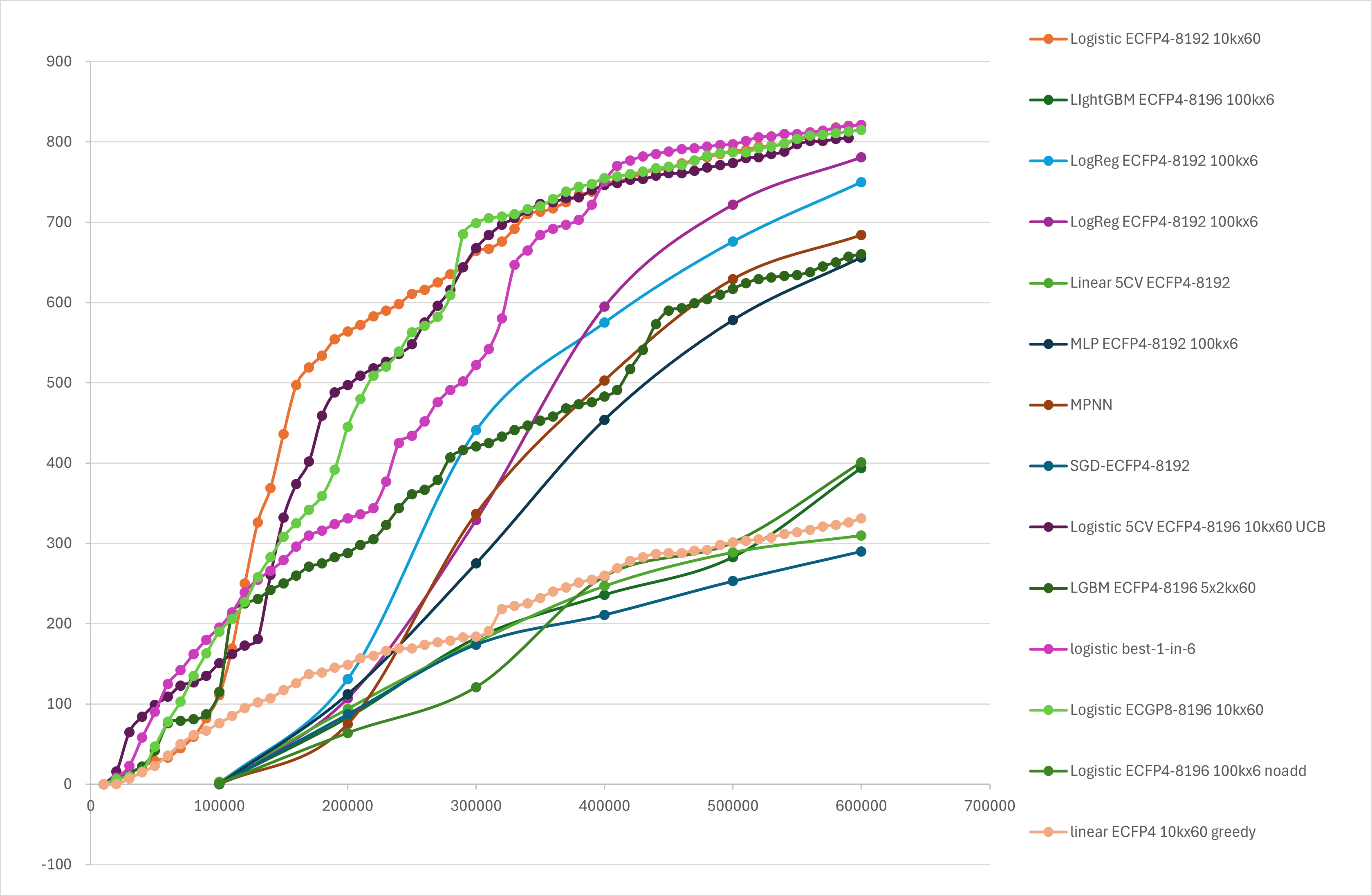 図11.XEDOCKを用いたドッキングスコアの能動学習の比較
図11.XEDOCKを用いたドッキングスコアの能動学習の比較
これに費やした計算リソースは、AzureのF16-v2 のVM(16CPU)1ノードで3時間程度でした。より大きなデータセットではさらに高性能なVMを使うことで十分に対応可能と考えられます。
このブログでは、低分子化合物のドッキングシミュレーションによるバーチャルスクリーニングの例を挙げました。活用の方法としては低分子やドッキングに限定されるものではなく、入出力のインターフェースを追加で実装することにより、ほかのオブジェクトやスコアリング、また物性、活性の予測モデルを作るような用途にも応用できます。
さいごに
XEDOCKシステムは、ゼウレカ独自で開発しており、弊社のプロダクトとしてもご紹介しています。ご要望に応じてドッキング以外のスコアリングやサンプリングなどの拡張も可能です。また、対象は低分子化合物に限られず、新モダリティーへの対応も可能ですので、ご興味のある方は下記のコンタクトページよりお気軽にお問い合わせください!